
Технология RPC и ее реализацию с помощью Rabbit MQ и Pika.
В данном посте мы построим используя RabbitMQ распределенную RPC систему: клиент и массштабируемый RPC сервер. В качестве нагрузки используем медленный RPC сервис выполняющий рассчет числа Фибоначи.
# Технология RPC и ее применение.
Цитируя Википедию (opens new window)
Удалённый вызов процедур (от англ. Remote Procedure Call, RPC) — класс технологий, позволяющих компьютерным программам вызывать функции или процедуры в другом адресном пространстве (на удалённых компьютерах, либо в независимой сторонней системе на том же устройстве).
Таким образом реализуя механизм RPC призван реализовать возможность вызова функции на удаленной машине, при этом клиент использует данный вызов как обычный вызов функции. RPC эффективен в случае когда между клиентом и сервером реализующем выполнение удаленной процедуры существует связь с небольшим временем ответов и относительно малым количеством предаваемых данных. Удаленные процедуры обладают следующими чертами:
- Асимметричность, одна из взаимодействующих сторон является инициатором (в терминах RabbitMQ - Consumer);
- Синхронность, т.е выполнение функции на стороне клиента приостанавливается с момента выдачи запроса и возобновляется после возврата результата из вызываемой процедуры.
Основные случаи когда может применятся RPC:
- Распределенные вычисления (когда выполнение ресурсоемких задач распределяется между несколькими серверами);
- Распределенное тестирование (например проверка работоспособности тестов на различных платформах);
- Удаленное администрирование (управление конфигурационными файлами с единого узла);
- Тунелирование (выход за границы маршутизируемой сети).
# Подготовка проекта
Для реализации мы используем брокер сообщений Rabbit MQ (opens new window) и его клиент для Python - Pika (opens new window). Далее предполагается, что все действия выполняются в Linux среде.
Для начала работы нам потребуется брокер сообщений Rabbit MQ (opens new window). Он может быть установлен и запущен локально, либо запущен в контейнере Docker. Docker образ (opens new window) позволяет запустить полностью настроенный сервер Rabbit MQ с веб-менеджером в котором можно наблюдать его работу. Для запуска Rabbit MQ в контейнере Docker запустим следующую команду:
docker run -it --rm --name rabbitmq -p 5672:5672 -p 8080:15672 rabbitmq:3-management
Когда образ будет запущен обратившись из браузера по адресу localhost:8080 мы должны увидеть окно входа в RabbitMQ Manager. Логин и пароль по умолчанию:
login: guest
password: guest
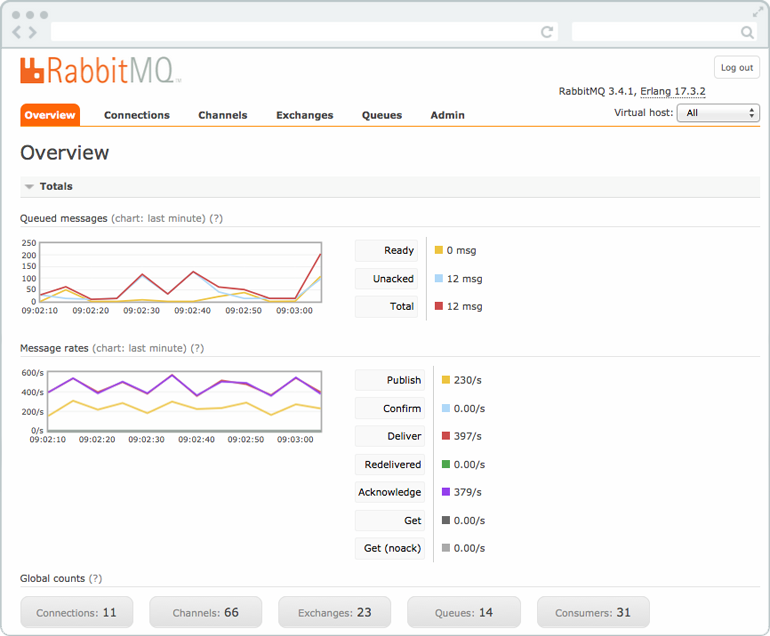
Из данного интерфейса мы можем наблюдать наши очереди, количество запросов в обработке и возвращенных, производить управление очередями (удалять, очищать) и т.д. Интерфейс Менеджера интуитивно понятен и его описание выходит за пределы данного поста.
Создаем папку нашего проекта запускаем внутри виртуальное окружение Python и устанавливаем пакет Pika:
mkdir rpc_example
cd rpc_example
python -m venv venv
source vevn/bin/activate
pip install pika
Далее в папке rpc_example с помощью любого удобного редактора создаем файлы rpc_server.py и rpc_client.py код которых будет приведен далее в посте.
# Интерфейс клиента
В качестве клиента мы создадим класс FibonacciRpcClient. В котором реализуем метод call, который в свою очередь отправляет RPC запрос и блокируется до тех пор пока не будет получен ответ. Как было сказано выше одна из черт RPC - синхронность. Таким образом в дальнейшем метод call класса FibonacciRpcClient может быть вызван из клиентского кода как обычный метод, механизм обращения к удаленной процедуре при этом будет скрыт.
При этом могут возникать проблемы, когда программист не знает, является ли вызов функции локальным или это медленный RPC. Отсутствие данной информации ведет к непредсказуемой системе и усложняет отладку. Неправильное использование RPC вместо упрощения кода может привести к обратным результатам. Поэтому рекомендуется следовать следующим советам:
- Убедитесь, что вполне ясно какой вызов функции является локальным, а какой удаленным.
- Задокументируйте свою систему. Сделайте зависимости между компонентами понятными.
- Реализуйте обработку ошибок. Продумайте, как должен реагировать клиент, когда сервер RPC не работает в течение длительного времени?
В случае сомнений избегайте RPC. По возможности следует использовать асинхронный конвейер - вместо блокировки, подобной RPC, в котором результаты асинхронно передаются на следующий этап вычислений.
В общих чертах RPC поверх RabbitMQ реализуется довольно просто. Клиент отправляет сообщение запроса и сервер отвечает сообщением с ответом. Чтобы получить ответ, клиент должен отправить с запросом адрес очереди в которую будет возвращен ответ "callback_queue".
result = channel.queue_declare(queue='', exclusive=True)
callback_queue = result.method.queue
channel.basic_publish(exchange='',
routing_key='rpc_queue',
properties=pika.BasicProperties(
reply_to = callback_queue,
),
body=request)
# ... далее код который читает ответ из очереди callback_queue ...
# Параметры сообщений reply_to и correlation_id
Протокол AMQP 0-9-1 предопределяет набор из 14 параметров, связанных с сообщениями. Большинство свойств используются редко, за исключением следующих:
- delivery_mode: помечает сообщение как постоянное/хранимое (со значением 2) или временное (любое другое значение).
- content_type: используется для описания mime-типа кодировки. Например, для JSON рекомендуется установить значение:
application/json.- reply_to: обычно используется для обозначения очереди обратного вызова.
- correlation_id: является полезным для сопоставления ответов RPC с запросами.
В методе приведенном выше мы предположили использование callback очередь для каждого RPC запроса. Это крайне неэффективно, но к счастью есть гораздо лучшее решение - создать одну очередь callback_queue для клиента.
Что порождает новый вопрос. Как сопоставить друг с другом вопросы и ответы при использовании одной очереди. Здесь на помощь приходит параметр correlation_id. Мы можем присваивать уникальное значение данному параметру для каждого запроса. В дальнейшем когда ответ будет возвращен в очередь callback_queue мы сравниваем данный параметр с параметром переданным в запросе и если они совпадают, значит ответ относится к данному запросу. Если значение correlation_id неизвестно, мы безопасно игнорируем его - данное сообщение не принадлежит нашему запросу.
Возникает вопрос, почему мы игнорируем неизвестные сообщения в callback_queue, вместо того, чтобы выбросить ошибку. Это связано с вероятностью возникновения состояния гонки на стороне сервера. Хотя это маловероятно, возможно, что RPC-сервер перестанет отвечать сразу после отправки нам ответа, но до отправки сообщения подтверждения для запроса. Если это произойдет, перезапущенный сервер RPC снова обработает запрос. Вот почему на клиенте мы должны корректно обрабатывать повторяющиеся ответы, а RPC в идеале должен быть идемпотентным (давать тот же результат при повторном применении операции к объекту).
# Схема работы RPC
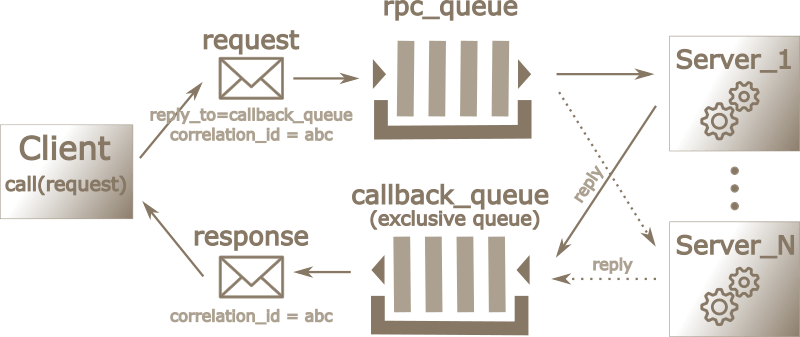
Наш RPC работает следующим образом:
- Когда клиент стартует, он создает анонимную эксклюзивную очередь
callback_queue. - В качестве RPC запроса, клиент отправляет сообщение с двумя параметрами:
reply_to, которое устанавливает очередь в которую будут направлены ответыcallback_queueиcorrelation_idкоторый устанавливает уникальное значение для каждого запроса. - Запрос отправляется в очередь
rpc_queue - Обработчик RPC (сервер) слушает очередь
rpc_queueи когда запрос появляется в ней - выполняет задачу и отправляет ответ обратно клиенту используя очередь указанную в полеreply_to = callback_queue. - Клиент в свою очередь слушает очередь
callback_queue. Когда сообщение приходит, клиент проверяет свойствоcorrelation_id. Если значение совпадает со значением переданным в запросе - возвращает ответ в приложение.
# Код сервера
Собрав все воедино получим следующий код для RPC сервера:
rpc_server.py
# rpc_server.py
import pika
connection = pika.BlockingConnection(
pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='rpc_queue')
def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n - 1) + fib(n - 2)
def on_request(ch, method, props, body):
n = int(body)
print(" [.] fib(%s)" % n)
response = fib(n)
ch.basic_publish(exchange='',
routing_key=props.reply_to,
properties=pika.BasicProperties(correlation_id = \
props.correlation_id),
body=str(response))
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(queue='rpc_queue', on_message_callback=on_request)
print(" [x] Ожидание RPC запроса")
channel.start_consuming()
Код сервера довольно прост:
- Начинаем мы с установки соединения и объявления очереди
rpc_queue. - Далее мы объявляем функцию фибоначи
fib(). Она предполагает передачу только валидного положительноintна вход. - Мы объявляем функцию обратного вызова
on_requestдляbasic_consume- ядро RPC сервера. Она выполняется как только запрос получен. Выполняет работу и отправляет ответ обратно. - Мы можем запустить более чем один процесс сервера. Чтобы распределить нагрузку эквивалентно среди нескольких серверов нам необходимо установитть
prefetch_count.
# Код клиента
rpc_client.py
# rpc_client.py
import pika
import uuid
class FibonacciRpcClient(object):
def __init__(self):
self.connection = pika.BlockingConnection(
pika.ConnectionParameters(host='localhost'))
self.channel = self.connection.channel()
result = self.channel.queue_declare(queue='', exclusive=True)
self.callback_queue = result.method.queue
self.channel.basic_consume(
queue=self.callback_queue,
on_message_callback=self.on_response,
auto_ack=True)
def on_response(self, ch, method, props, body):
if self.corr_id == props.correlation_id:
self.response = body
def call(self, n):
self.response = None
self.corr_id = str(uuid.uuid4())
self.channel.basic_publish(
exchange='',
routing_key='rpc_queue',
properties=pika.BasicProperties(
reply_to=self.callback_queue,
correlation_id=self.corr_id,
),
body=str(n))
while self.response is None:
self.connection.process_data_events()
return int(self.response)
fibonacci_rpc = FibonacciRpcClient()
print(" [x] Запрошен fib(30)")
response = fibonacci_rpc.call(30)
print(" [.] Получен %r" % response)
Клиентский код несколько более сложен:
- Мы устанавливаем соединение, получаем канал и объявляем эксклюзивную очередь
callback_queueдля ответов. - Мы подписываемся на
callback_queueи теперь можем принимать RPC ответы. - В функции обратного вызова
on_responseкоторая выполняется для каждого ответа мы выполняем простую работу: для каждого ответа проверяемcorrelation_idна соответствие запросу. Если совпадает, сохраняем ответ вself.responseи закрываемconsuming loop. - Далее мы определяем метод
callкоторый отправляет RPC запрос. - В методе
callмы генерируем уникальныйcorrelation_id. Функцияon_responseиспользует его значение чтобы перехватить соответствующий ответ. - Также в методе
call, мы формируем сообщение запроса, с 2-мя свойствамиreply_toиcorrelation_id. - В конце мы ожидаем пока соответствующий ответ будет возвращен и отдаем ответ обратно в приложение.
Теперь наш RPC может быть запущен в работу. Для этого необходимо в терминале запустить сервер:
python rpc_server.py
# => [x] Awaiting RPC requests
В другом терминале мы можем отправить запрос на расчет числа Фибоначи:
python rpc_client.py
# => [x] Requesting fib(30)
# Заключение
Представленный дизайн - не единственная возможная реализация RPC-сервиса, но он имеет ряд важных преимуществ:
- Если сервер RPC работает слишком медленно, вы можете масштабировать его, просто запустив другой.
- На стороне клиента RPC требует отправки и получения только одного сообщения. Никаких синхронных вызовов, таких как
queue_declare, не требуется. В результате клиенту RPC требуется только один сетевой круговой обход для одного запроса RPC.
Код приведенный в данном посте сильно упрощен и не может быть использован в продакшн среде. Для доведения его до производственного уровня следует решить следующие вопросы:
- Как должен реагировать клиент, если серверы не работают?
- Должен ли клиент иметь какое-то время ожидания для RPC?
- Если сервер неисправен и вызывает исключение, следует ли его перенаправить клиенту?
- Защита от недействительных входящих сообщений (например, проверка границ) перед обработкой.