
Профилирование приложений Python
При разработке приложений периодически у разработчиков возникает вопрос - по какой причине реализованный код работает медленно, и где теряетсются драгоценные время и ресурсы? Здесь на помощь приходят инструменты профилирования. В текущем посте рассмотрим возможности профилирования приложений реализованных на Python с помощью различных инструментов профилирования, а также рассмотрим средства позволяющие строить графическое представление результатов профилирования и создавать отчеты.
# Профилирование как понятие
Для выявления мест где приложение растрачивает ресурсы нам потребуется следующая информация:
- порядок выполнения кода (какие функции в каком порядке вызываются);
- количество вызовов отдельных фрагментов кода (функций/процедур/методов и т.п.);
- время затрачиваемое на выполнение отдельного фрагмента кода (функции/метода/процедуры и т.п.);
Имея вышеуказанную информацию мы можем выявить узкие места в нашем проекте, и сконцентрировшись на отдельном фрагменте кода выполнить его рефакторинг для повышения эффективности выполнения приложения в целом.
Профиль - набор статистических данных который описывает как часто и долго выполнялись различные части программы. (The Python Profilers (opens new window))
# Инструменты профилирования Pyhton
# cProfile и profile
Python имеет встроенные инструменты для выполнения профилирования, которые находятся в модулях cProfile и profile. Данные модули позволяют получить статистику, которая в дальнейшем может быть преобразована в отчет с помощью модуля pstats или других инструментов. Модуль cProfiles реализован как Си расширение с невысоким оверхедом и рекомендован для использования как основной. Официальная документация здесь: The Python Profilers (opens new window).
Создадим небольшое приложение Python в котором осуществляется вызов нескольких функций и вывод сообщений в консоль разместим код в модуле test.py
def print_message(message):
print(message)
def range_output(external_step, internal_steps_number):
for internal_step in range(internal_steps_number):
print_message(f'[{external_step}: {internal_step}]')
def main():
for i in range(3):
range_output(external_step=i, internal_steps_number=2)
if __name__ == '__main__':
main()
Выполним профилирование данного кода с помощью cProfile:
python -m cProfile test.py
[0: 0]
[0: 1]
[1: 0]
[1: 1]
[2: 0]
[2: 1]
19 function calls in 0.000 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.000 0.000 test.py:10(main)
1 0.000 0.000 0.000 0.000 test.py:3(<module>)
6 0.000 0.000 0.000 0.000 test.py:3(print_message)
3 0.000 0.000 0.000 0.000 test.py:6(range_output)
1 0.000 0.000 0.000 0.000 {built-in method builtins.exec}
6 0.000 0.000 0.000 0.000 {built-in method builtins.print}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
В результате мы получили интересующую нас информацию:
- ncalls - количество вызовов функции;
- tottime - общее время затраченное в данной функции (без учета времени затраченного на вызовы подфункций);
- percall - время затраченное на 1 вызов функции (tottime / ncalls);
- cumtime - общее время затраченное в данной функции, включая время затраченное на вызов всех подфункций (от вызвова до выхода). Данная величина верна и для рекурсивных функций;
- percall - время затраченное на 1 вызов функции (cumtime / ncalls);
- filename:lineno(function) - соответсвенно <имя файла>:<№ строки>(<имя функции>)
Также мы можем созадть файл в формате pstats для использования в качестве данных инструментов построения графических отчетов (рассмотрены далее), что реализуется череез флаг -o с указаинием имени файла с расширением .pstats например cprofile_output.pstats:
python -m cProfile -o cprofile_output.pstats test.py
# Yappi
Библиотека Yappi (opens new window) ("Yet Another Python Profiler") - обладает более широким функционалом, чем встроенные средства Python. Yappi реализованная как Си библиотека - является быстрой, позволяет выполнить профилирование многопоточных приложений, приложений использующих asyncio (opens new window) и gevent (opens new window), позволяет вывести результаты в формате callgind (opens new window) и pstat (opens new window), в результататы работы профилировщика могут отображать Wall time (opens new window) или CPU Time (opens new window) и могут быть агрегированы из разных сеансов. Кроме того при использовании PyCharm профилировщик Yappi используется в данной IDE по умолчанию.
Установка Yappi осуществляется следующим образом:
pip install yappi
Теперь немного изменим наш код, чтобы Yappi мог выполнить его анализ и собрать статистику в форматах pstat и callgrind:
import yappi
def print_message(message):
print(message)
def range_output(external_step, internal_steps_number):
for internal_step in range(internal_steps_number):
print_message(f'[{external_step}: {internal_step}]')
def main():
for i in range(3):
range_output(external_step=i, internal_steps_number=2)
if __name__ == '__main__':
yappi.start() # Здесь начинается наблюдение за выполняемым кодом
main()
func_stats = yappi.get_func_stats() # Собираем статистику выполненных функций
func_stats.print_all() # Выведем в консоль собранную статистику
func_stats.save('yappi_output.pstats', 'PSTAT') # Сохраняем в формате pstat
func_stats.save('yappi_output.callgrind', 'CALLGRIND') # Сохраняем в формате callgrind
yappi.stop() # Останавливаем наблюдение
yappi.clear_stats() # Очищаем статистику
Выполнение данного кода создаст файл output.pstats который может быть обработан с помощью ранее рассмотренного gprof2dot, и файл output.callgrind в формате callgrind (как использовать рассмотрим ниже) и выведет результаты профилирования в консоль:
python test.py
Clock type: CPU
Ordered by: totaltime, desc
name ncall tsub ttot tavg
..ver/MarketAnalyser/test.py:10 main 1 0.000017 0.000141 0.000141
..ketAnalyser/test.py:6 range_output 3 0.000029 0.000125 0.000042
..etAnalyser/test.py:3 print_message 6 0.000028 0.000095 0.000016
Здесь отображается:
- Clock type: CPU - указывает, что показанная статистика времени профилирования извлекается с использованием тактовой частоты ЦП. Это означает, что отображается фактическое время процессора, затраченное на функцию.
- Ordered by: totaltime, desc - показывает параметр по которому выполнена сортировка и ее порядок, в нашем случае сортировка выполнена по итоговому времени (totalitme) в порядке убывания
- name - полное уникальное имя вызываемой функции
- ncall - количество вызовов функции
- tsub - общее время, затраченноей функцией, без дополнительных вызовов
- ttot - общее время, затраченное функцией, включая вспомогательные вызовы
- tavg - среднее время, затраченноей функцией, включая вспомогательные вызовы.
Главное преимущество yappi - это реализация профилирования в многопоточных приложениях и корутинах. Более подробную информацию и примеры реализации можно посомтреть на GitHub странице проекта (opens new window).
# Построение отчетов по результатам профилироваяния
Информация полученная с помощью вышеуказанных средств профилирования весьма полезна, но вывод ее не очень удобен для анализа, особенное в случае с реальным приложением где количество фрагментов кода и их вызовов будет огромным. По этой причине зачастую требуется помощь дополнительных инструментов позволяющих в графическом виде проанализировать данную информацию.
# gprof2dot
Библиотека gprof2dot (opens new window), позволяет преобразовать вывод результатов профилирования в формате pstat преобразовать в удобный график вызовов функций который для итогового приложения может выглядесть следюущим образом (график со страницы проекта (opens new window)):

gprof2dot для построения графики испоьлзует библиотеку graphviz. Для установки в ОС Linux необходимо выполнить следующие команды:
sudo apt install graphviz
pip install gprof2dot
Теперь отобразим графики вызовов, созданные нами ранее с помощью gprof2dot которые будут сохранены в формате png:
gprof2dot -f pstats cprofile_output.pstats | dot -Tpng -o cprofile_output.png
gprof2dot -f pstats yappi_output.pstats | dot -Tpng -o yappi_output.png
Откроем изображение cprofile_output.png:
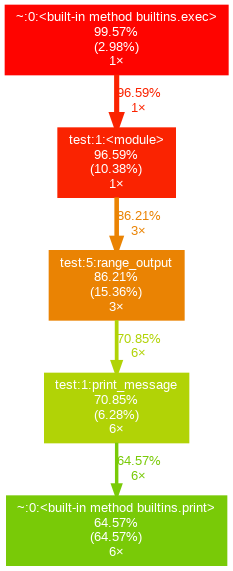
Здесь мы наглядно видим что 86.21% времени выполнения заняло выполнение функции range_output и данный метод был вызван 3 раза и за это время он 6 раз вызвал метод print_message. Таким образом с помощью gprof2dot можно строить удобные графические представления для профилирования.
Граф полученные в результате работы yappi выглядит несколько короче по причине того что запись ведется с момента указанного в коде:
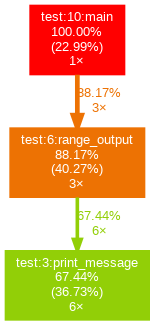
Здесь аналогично с примером cProfile мы видим граф вызовов функций с начала записи yappi.start() до завершения yappi.stop().
Как мы видим инструмент gprof2dot позволяет нам строить графические представления последовательностей вызовов функций нашего приложения с указанием количества вызовов и затрачиваемых ресурсов. Но Yappi позволяет кроме того выполнить вывод результатов профилирования в формате Valgrind который называется callgrind (opens new window). Соответственно данный формат может быть открыт сторонними приложениями умеющими работать с ними одним их таких является KCachegrind.
# KCachegrind
Cоздав файл в формате callgrind мы можем использовать продвинутые средства для просмотра результатов профилирования `KCachegrind (opens new window). В среде Debian она может быть установлена:
sudo apt install kcachegrind
После установки, запускем приложение kcachegrind и открываем созданный нами файл outpul.callgrind и получаем подробнейший интерактивный отчет:
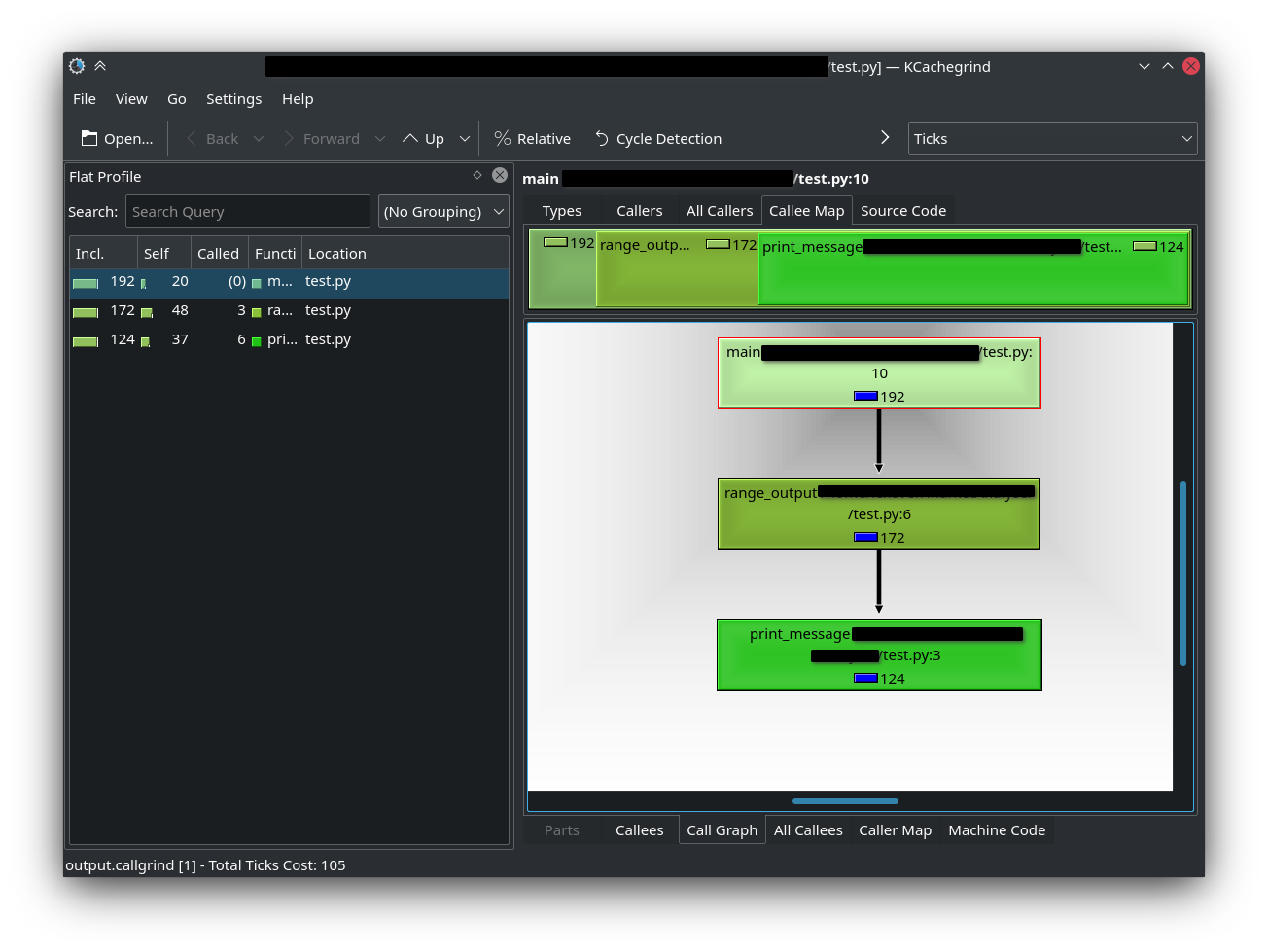
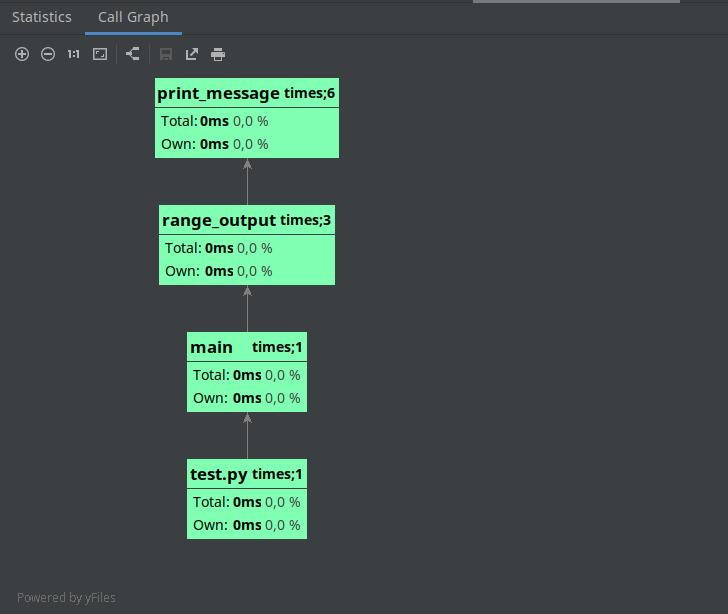
# PyCharm Profilе
Также если вы используете в работе IDE PyCharm Pro, данная IDE по умолчанию использует Yappi как профайлер и имеет встроенные средства для графического отображения результатов профилирования и запустив профилирование в IDE мы получаем отчет в виде таблицы и графического представления:
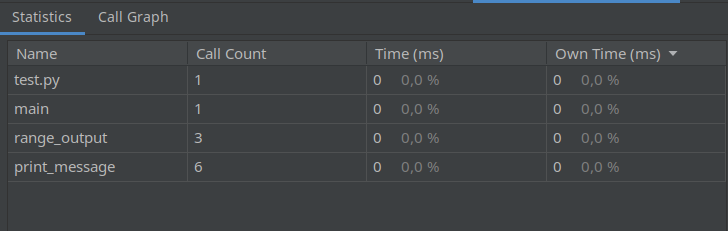
# Выводы
Для Python реализовано множество инструментов позволяющих выполнить профилирование кода и выявить узкие места. В данном посте охвчена лишь небольшая их часть. Хотелось бы отметить интересные библиотеки не охваченные текущей статьей:
- Pyinstrument (opens new window), которая имеет встроенные средства профилирования для проектов Django и Flask;
- Pyflame (opens new window) - статический профайлер для Python созданный Uber и позволяющий строить впечатляющие графики для сложных приложений.